
Ada banyak algoritma Machine Learning yang bisa diterapkan dalam distribusi data. K Nearest Neigbors (KNN), Support Vector Machine (SVM) dan Naive Bayes adalah tiga diantaranya.
K Nearest Neigbors
K Nearest Neighbors (KNN) adalah yang sangat sederhana, mudah dimengerti, serbaguna dan salah satu algoritma pembelajaran mesin teratas.
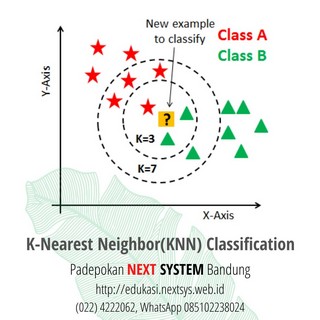
KNN digunakan dalam berbagai aplikasi seperti keuangan, kesehatan, ilmu politik, deteksi tulisan tangan, pengenalan gambar dan pengenalan video. Dalam peringkat Kredit, lembaga keuangan akan memprediksi peringkat kredit pelanggan. Dalam penyaluran pinjaman, lembaga perbankan akan memprediksi apakah pinjaman itu aman atau berisiko. Dalam ilmu politik, mengklasifikasikan calon pemilih dalam dua kelas akan memilih atau tidak akan memilih.
Algoritma KNN digunakan untuk masalah klasifikasi dan regresi. Algoritma KNN berdasarkan pendekatan fitur kesamaan.
Support Vector Machine
SVM menawarkan akurasi yang sangat tinggi dibandingkan dengan pengklasifikasi lain seperti regresi logistik, dan pohon keputusan. Ia dikenal karena trik kernelnya untuk menangani ruang input nonlinier. Ini digunakan dalam berbagai aplikasi seperti deteksi wajah, deteksi intrusi, klasifikasi email, artikel berita dan halaman web, klasifikasi gen, dan pengenalan tulisan tangan.
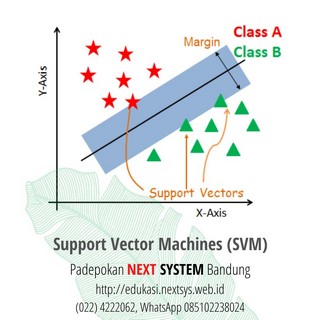
SVM adalah algoritma yang menarik dan konsepnya relatif sederhana. Pengklasifikasi memisahkan titik data menggunakan hyperplane dengan jumlah margin terbesar. Itu sebabnya classifier SVM juga dikenal sebagai classifier diskriminatif. SVM menemukan hyperplane optimal yang membantu dalam mengklasifikasikan poin data baru.
Naive Bayes
Misalkan Anda adalah seorang manajer produk, Anda ingin mengklasifikasikan ulasan pelanggan dalam kelas positif dan negatif. Atau Sebagai manajer pinjaman, Anda ingin mengidentifikasi pemohon pinjaman mana yang aman atau berisiko? Sebagai analis layanan kesehatan, Anda ingin memprediksi pasien mana yang dapat menderita penyakit diabetes. Semua contoh memiliki jenis masalah yang sama untuk mengklasifikasikan ulasan, pemohon pinjaman, dan pasien.

Naive Bayes adalah algoritma klasifikasi paling mudah dan cepat, yang cocok untuk sebagian besar data. Klasifikasi Naive Bayes berhasil digunakan dalam berbagai aplikasi seperti penyaringan spam, klasifikasi teks, analisis sentimen, dan sistem pemberi rekomendasi. Ia menggunakan teorema Bayes probabilitas untuk prediksi kelas yang tidak diketahui.
…
Untuk informasi lebih lanjut mengenai kelas pelatihan Computer Vision, Machine Learning dan Deep Learning, silahkan menghubungi kontak tertera.