Jurnal ini sudah disiapkan sejak satu tahun lalu. Namun, dikarenakan sejumlah kesibukan, akhirnya baru dikerjakan di tahun 2025 ini, dan sudah published pada tanggal 8 Mei 2025, melalui publisher Kinetik, yang memiliki akreditasi Sinta 2.

The growing integration of photovoltaic (PV) systems into power grids presents new challenges. These challenges arise from the inherent variability in PV output, especially during rapid weather changes. Consequently, accurate forecasting becomes essential for maintaining grid stability. However, many existing methods fail to capture short-term fluctuations effectively. To address this gap, ultra-short-term PV power prediction—within seconds—offers a promising solution. This study develops an optimized BiLSTM-Dense model to improve forecasting accuracy over a 30-second horizon. By adding a dense layer, the model can better learn complex temporal patterns and data dependencies.
For this purpose, the study uses a dataset collected in late 2023. The dataset includes solar irradiance, PV output power, surface temperature, ambient temperature, humidity, and wind speed. Before modeling, the data undergo normalization and smoothing. These steps help improve signal clarity and model robustness. Next, a grid search tunes the model’s hyperparameters. The process focuses on choosing the best optimizer and activation function. As a result, the Adam optimizer combined with the Swish function yields the best performance. The model achieves an MAE of 0.00271 and an RMSE of 0.00806. These outcomes indicate strong accuracy over ultra-short-term forecasting horizons.
Compared to the baseline, the BiLSTM-Dense model shows improved performance. It reduces MAE and RMSE by 0.52% and 2.19%, respectively, compared to the standard BiLSTM. Moreover, it surpasses the LSTM model with 4.00% lower MAE and 2.65% lower RMSE. Most notably, the model significantly outperforms ARIMA. It cuts MAE by 98.87% and RMSE by 97.21%. Therefore, these results highlight the model’s strength in learning non-linear and bidirectional temporal dependencies. Simpler models like ARIMA and unidirectional LSTM often fail to capture such complexity.
Sumber: https://kinetik.umm.ac.id/index.php/kinetik/article/view/2127



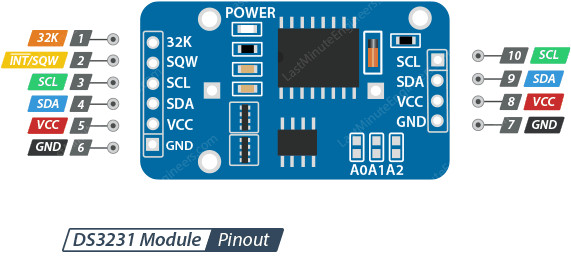 Pin SQW pada modul DS3231 menggunakan konfigurasi open-drain, sehingga memerlukan resistor pull-up agar dapat menghasilkan level logika yang benar. Resistor pull-up dengan nilai sekitar 4,7 kΩ hingga 10 kΩ dihubungkan antara pin SQW dan VCC (baik 3,3 V maupun 5 V) untuk memastikan sinyal square wave dapat berfungsi dengan stabil dan dapat dibaca dengan baik oleh sistem.
Pin SQW pada modul DS3231 menggunakan konfigurasi open-drain, sehingga memerlukan resistor pull-up agar dapat menghasilkan level logika yang benar. Resistor pull-up dengan nilai sekitar 4,7 kΩ hingga 10 kΩ dihubungkan antara pin SQW dan VCC (baik 3,3 V maupun 5 V) untuk memastikan sinyal square wave dapat berfungsi dengan stabil dan dapat dibaca dengan baik oleh sistem.








